


MOSS-TTSD是什么
MOSS-TTSD(Text to Spoken Dialogue)是清华大学语音与语言实验室与腾讯AI Lab联合开发的开源语音生成模型。该模型能将文本对话转化为自然流畅的语音,支持中英文双语生成。它结合了先进的语义-音学神经网络和大规模预训练语言模型,利用超过100万小时单人语音和40万小时对话语音数据进行训练。MOSS-TTSD支持零样本语音克隆,可以根据对话脚本精确生成对话者切换的语音,广泛应用于AI播客、访谈和新闻报道等场景。
MOSS-TTSD的主要功能
- 高表现力对话语音生成:能够将对话脚本转化为自然且富有表现力的语音,精准捕捉对话中的韵律与语调。
- 零样本多说话人音色克隆:无需额外样本,通过对话脚本即可实现多说话人之间的音色切换与克隆。
- 中英双语支持:支持中文与英文两种语言,生成高质量的对话语音。
- 长篇语音生成:通过优化编解码器和训练框架,一次性生成超长语音,避免拼接时的不自然过渡。
- 完全开源且商业就绪:模型权重、推理代码和API接口均开源,支持免费商业使用。
MOSS-TTSD的技术原理
模型架构简介
MOSS-TTSD 基于 Qwen3-1.7B-base 模型进行微调,采用离散化语音建模思路。通过 8 层 RVQ(Residual Vector Quantization)将语音信号转换为离散 token 序列,并利用自回归方式结合 Delay Pattern 进行生成,最终由解码器还原为语音。
核心创新:XY-Tokenizer
语音离散化采用全新设计的 XY-Tokenizer,具备双阶段多任务学习流程:
- 阶段一:同时训练自动语音识别(ASR)与语音重建任务,实现语义和粗粒度声学信息的融合。
- 阶段二:固定编码器和量化器,仅训练解码器,引入重建损失和 GAN 损失,增强细节表现。
该 Tokenizer 在 1kbps 的比特率和 12.5Hz 的帧率下,兼顾语义和声学表达,性能优于同类 Codec。
数据规模与预训练
模型训练使用约 100 万小时的单说话人语音数据与 40 万小时的对话语音数据。数据经过严格筛选与标注,同时进行中英文 TTS 预训练,累积时长达 110 万小时,显著提升语音的韵律和表达力。
长语音生成能力
得益于超低比特率 Codec 的设计,MOSS-TTSD 支持最长 960 秒的一次性语音生成,有效避免拼接带来的断裂感,适用于长对话、播客等场景。
MOSS-TTSD的项目地址
- 项目官网:https://www.open-moss.com/en/moss-ttsd/
- Github仓库:https://github.com/OpenMOSS/MOSS-TTSD
- HuggingFace模型库:https://huggingface.co/fnlp/MOSS-TTSD-v0.5
MOSS-TTSD的应用场景
- AI 播客制作:可生成自然流畅的对话语音,模拟真实交流场景,助力高质量播客内容创作。
- 影视配音:支持中英文双语和零样本音色克隆,适合为影视剧中的多角色对话配音。
- 长篇访谈:支持最长 960 秒语音生成,一次性输出完整访谈音频,避免拼接导致的生硬过渡。
- 新闻播报:可用于生成自然、生动的对话式新闻语音,提高新闻内容的吸引力与可听性。
- 电商直播:适用于数字人带货等场景,通过自然对话语音吸引观众、增强互动体验。
☞☞☞☞☞☞ 一键启动包在右侧下载 ☞☞☞☞☞☞
效果展示
角色1参考音频
角色2参考音频
生成结果
快速上手指南
AI工具已经被打包成一键启动的版本,只需轻轻点击即可使用,无需再为环境配置中的各种问题烦恼,一切变得更加便捷高效。
电脑配置要求
- 操作系统:Windows 10/11 64位
- 内存:16G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡,30系及以上显卡
- CUDA:显卡驱动更新到最新后,支持的CUDA版本大于等于12.8版本
- 整合包解压完约19.9G,要留足硬盘空间
- 如果电脑配置不满足要求的话,点我使用4090最强性能运行!
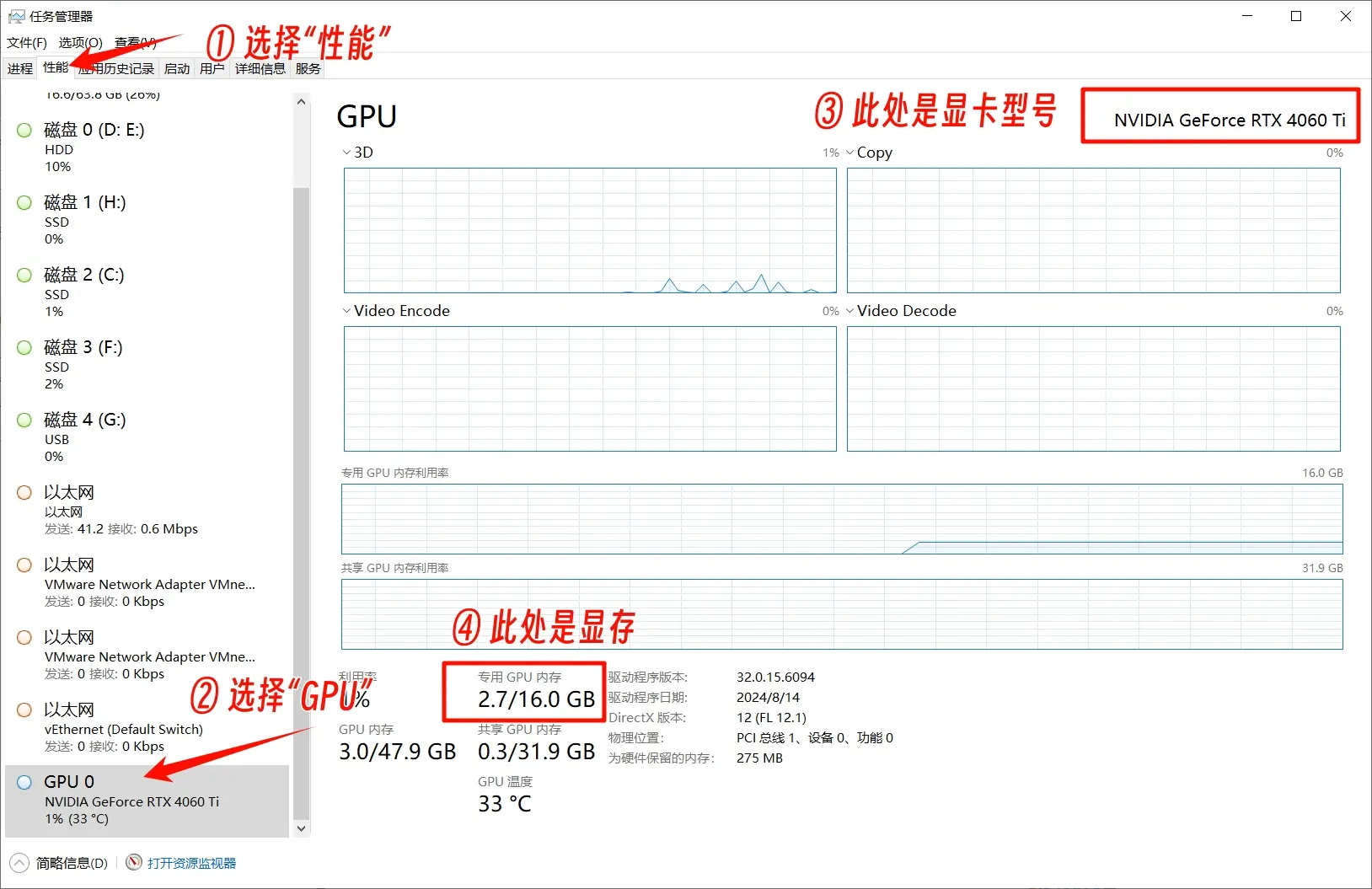
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
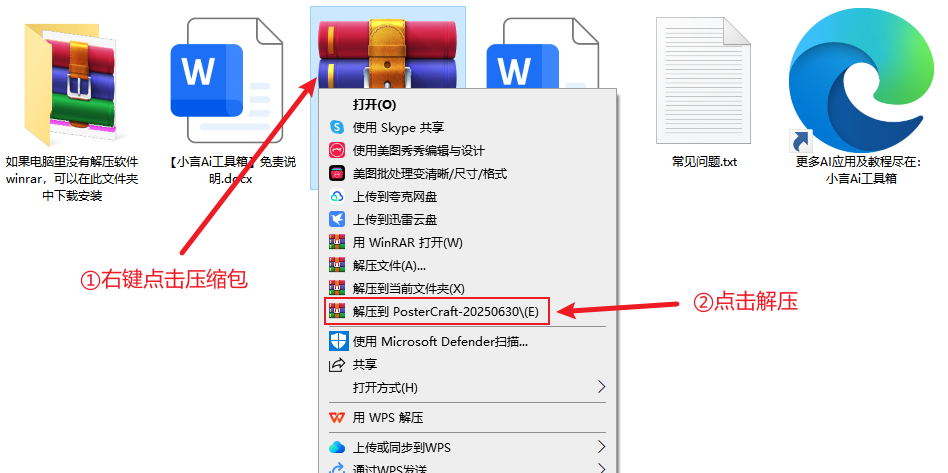
① 打开下载页面(https://xyanai.com/2017.html)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错
![]()
② 双击“启动程序.exe”,稍等片刻会在浏览器中自动打开操作界面

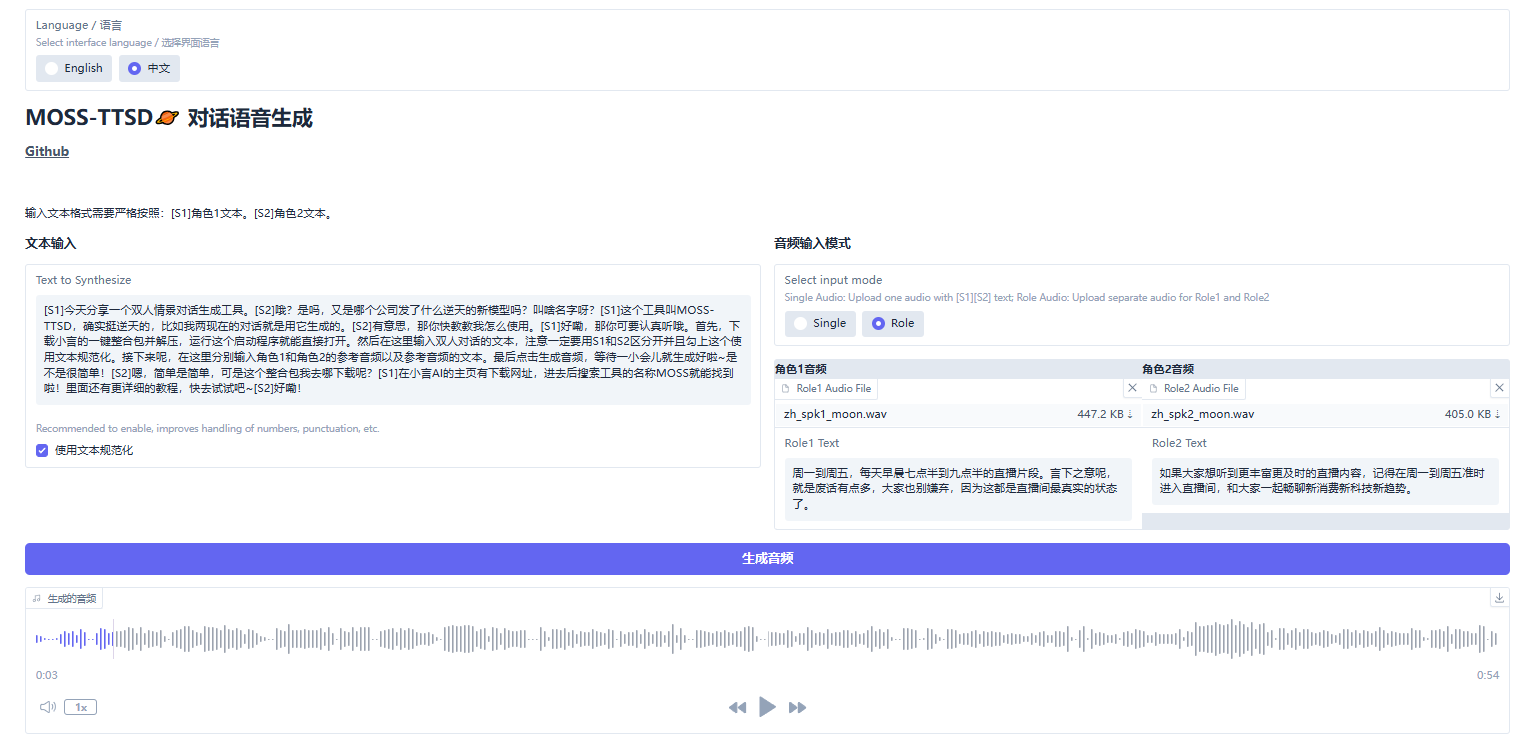
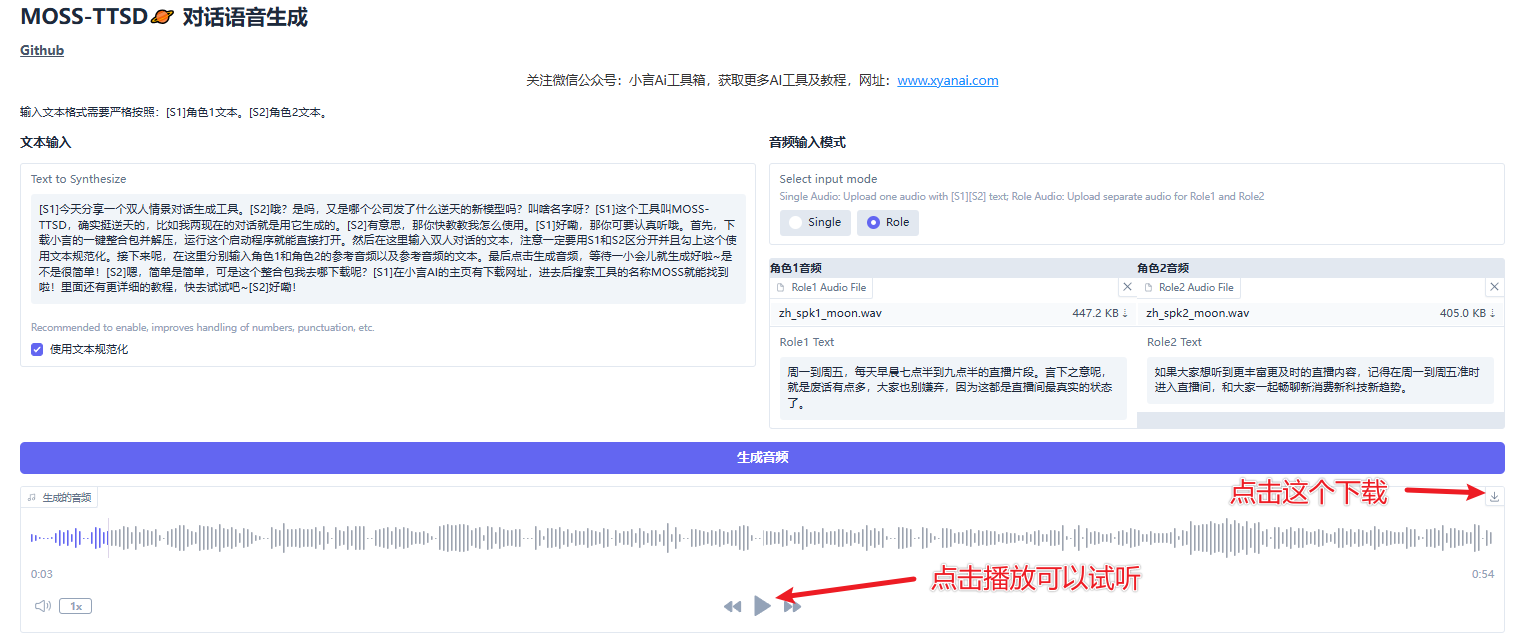
③使用时,先将界面语言切换为中文,然后按格式输入对话文本(例如:[S1]你好。[S2]你好啊)。接着选择输入模式,建议选择“Role”,分别上传角色1和角色2的音频,并在各自音频下方填写对应文本。最后点击“生成音频”即可。
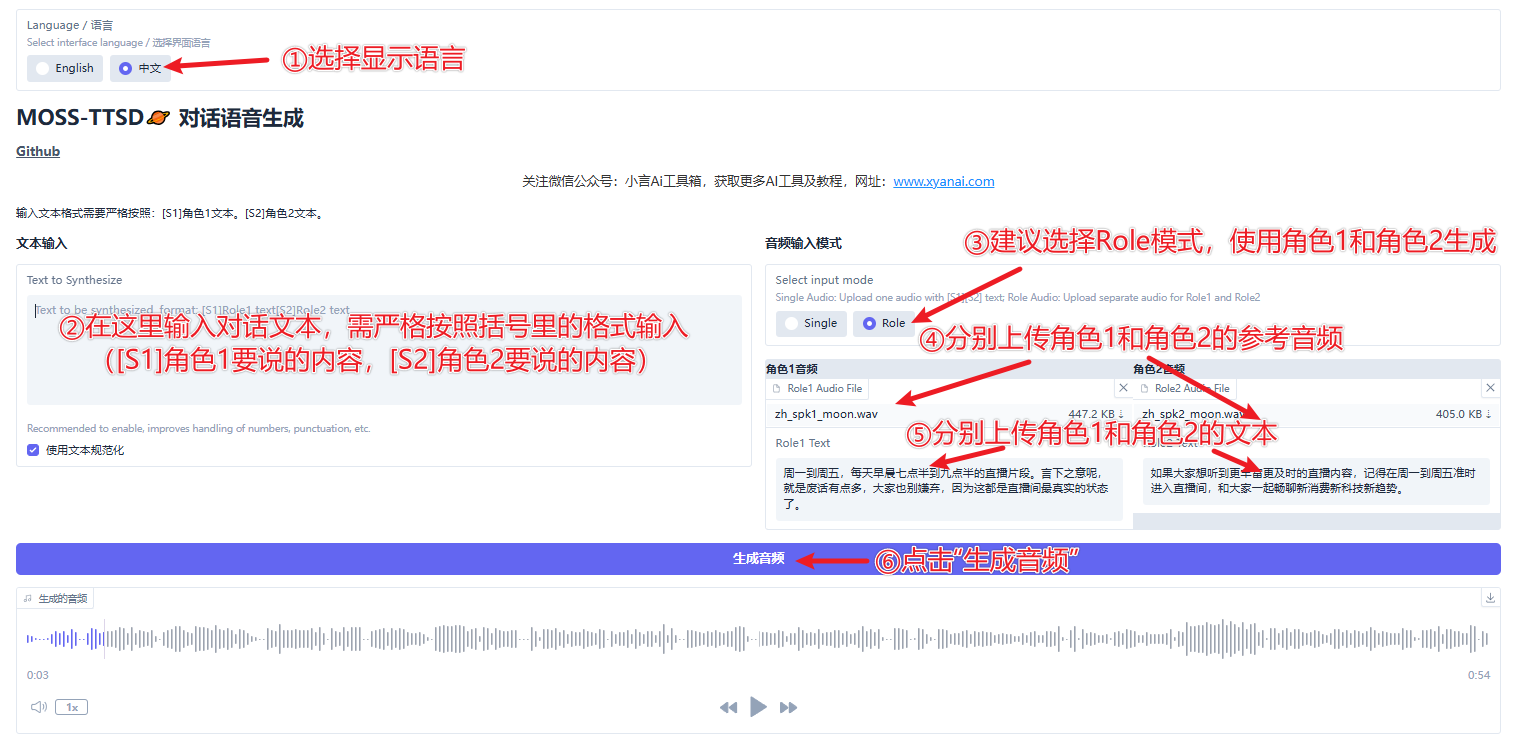
如下方示例所示,生成结果位于下方,点击播放按钮可以试听,点击生成结果右上角的下载按钮可以保存至指定文件夹
总结
MOSS-TTSD 是一个开源的对话语音生成模型,由清华大学与腾讯 AI Lab 联合开发。它支持中英文语音生成,具备自然流畅、富有表现力的对话语音输出能力,支持零样本音色克隆和超长语音生成。适用于播客、配音、访谈、新闻、电商等多种场景,模型完全开源,可免费商用。


