


ThinkSound是什么
ThinkSound是阿里通义语音团队最新发布的音频生成模型——ThinkSound。这是他们首个引入链式思考(CoT, Chain-of-Thought)机制的AI配音模型,专为视频配音场景设计,能够为每一帧画面精准生成匹配的音效。
传统音频生成模型往往难以把握画面的细节变化和空间关系,而ThinkSound通过模拟专业音效师的思维过程,引入三阶链式推理(基础音效识别 → 对象互动 → 指令调整),显著提升了音画同步的真实感。
它还搭载了专门构建的AudioCoT数据集,其中包含带有思维链注释的训练样本。实测中,ThinkSound在VGGSound数据集上全面超越了Seeing&Hearing、V-AURA、FoleyCrafter、Frieren、V2A-Mapper 和 MMAudio 等六种主流方法,展现了强劲的音频生成能力。
ThinkSound的主要功能
- 基础音效生成:模型会根据视频内容自动生成语义和时序匹配的音效,为画面提供初步的背景音环境。
- 对象级交互细化:用户可以点击视频中的任意对象,对其对应的音效进行个性化细化,让声音更精准贴合视觉细节。
- 指令驱动音频编辑:支持通过自然语言进行音频编辑,比如添加、删除或修改特定音效,极大提升了创作的灵活性和效率。
ThinkSound的技术原理
- 链式思考推理(CoT):将音频生成过程拆解为多个步骤,依次完成视觉动态分析、声学属性推断以及时间轴上的音效合成,模拟人类音效师的创作流程,让生成结果更具逻辑性和层次感。
- 多模态大语言模型(MLLM):借助如 VideoLLaMA2 等模型,提取视频中的时空和语义信息,构建结构化的 CoT 推理链,为后续音频生成提供清晰指引。
- 统一音频基础模型:采用条件流匹配技术,将视频、文本和音频上下文统一建模,实现高保真音频输出。该模型支持任意模态组合输入,灵活适配多种生成与编辑场景。
- 数据集支持:依托专门构建的 AudioCoT 数据集,模型可学习大量带有结构化思维链标注的样本,大幅提升其对音画关系的理解与生成能力。
ThinkSound的项目地址
- GitHub仓库:https://github.com/liuhuadai/ThinkSound
- HuggingFace模型库:https://huggingface.co/liuhuadai/ThinkSound
- arXiv技术论文:https://arxiv.org/pdf/2506.21448
ThinkSound的应用场景
- 影视制作:为电影、剧集和短视频生成真实自然的背景音效和场景声,让观众更好沉浸于剧情之中,显著提升音画融合的真实感。
- 游戏开发:自动生成符合游戏环境的动态音效和交互声效,增强玩家的代入感和沉浸体验,打造更生动的游戏世界。
- 广告与营销:为广告片段和社交媒体内容配上吸引人的音效与背景音乐,增强内容表现力,提高品牌记忆度与传播效率。
- 教育培训:在在线教学或模拟训练中生成贴合教学内容的音效,帮助学生更易理解和记忆,提高教学效果。
- VR/AR 应用:为虚拟和增强现实场景生成高度一致的环境音效和交互音效,让用户获得更沉浸、更真实的多感官体验。
☞☞☞☞☞☞ 一键启动包在右侧下载 ☞☞☞☞☞☞
视频介绍
快速上手指南
AI工具已经被打包成一键启动的版本,只需轻轻点击即可使用,无需再为环境配置中的各种问题烦恼,一切变得更加便捷高效。
电脑配置要求
- 操作系统:Windows 10/11 64位
- 内存:20G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡,30系及以上显卡
- CUDA:显卡驱动更新到最新后,支持的CUDA版本大于等于12.8版本
- 整合包解压完约52.8G,要留足硬盘空间
- 如果电脑配置不满足要求的话,点我使用4090最强性能运行!
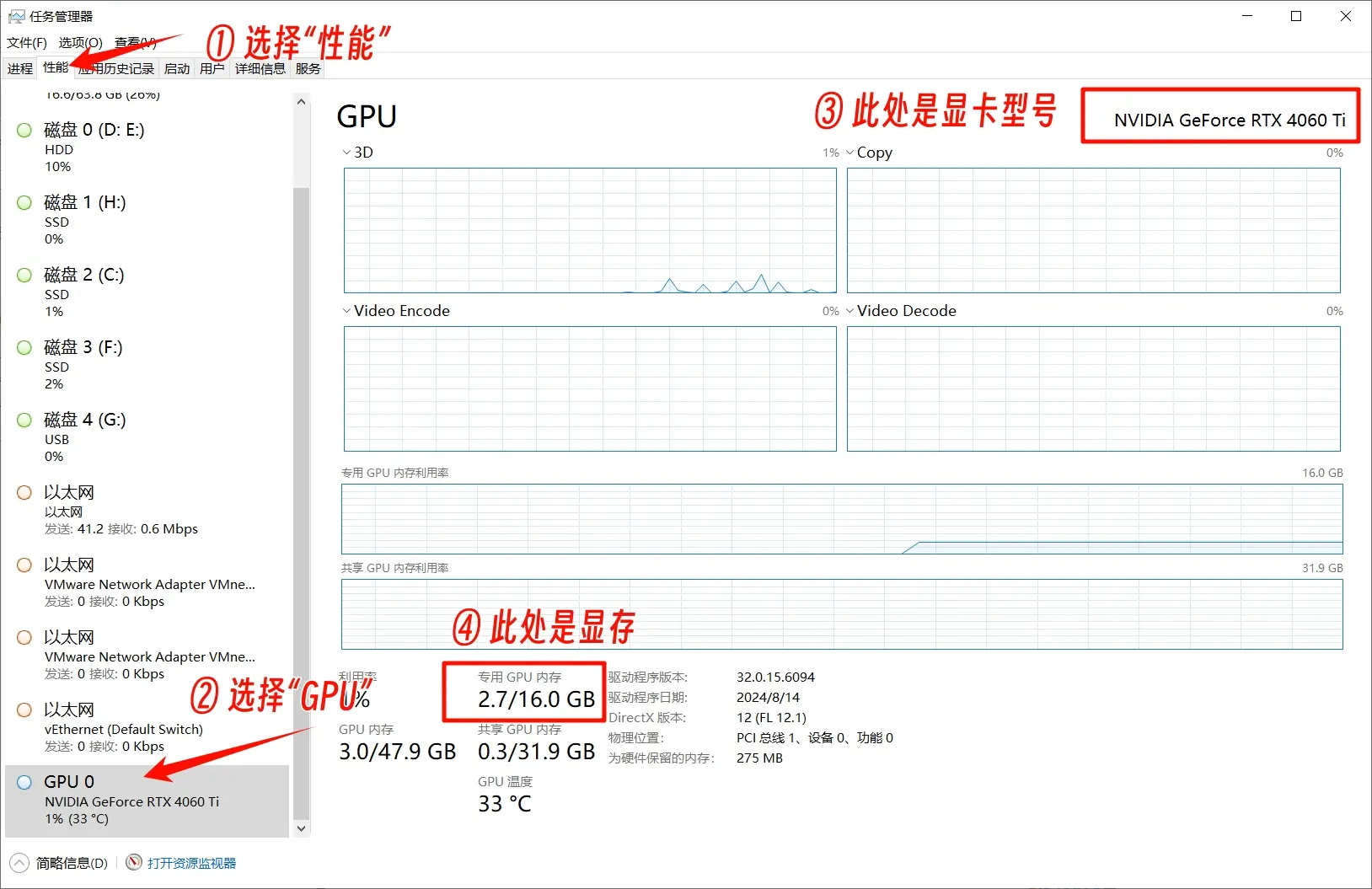
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
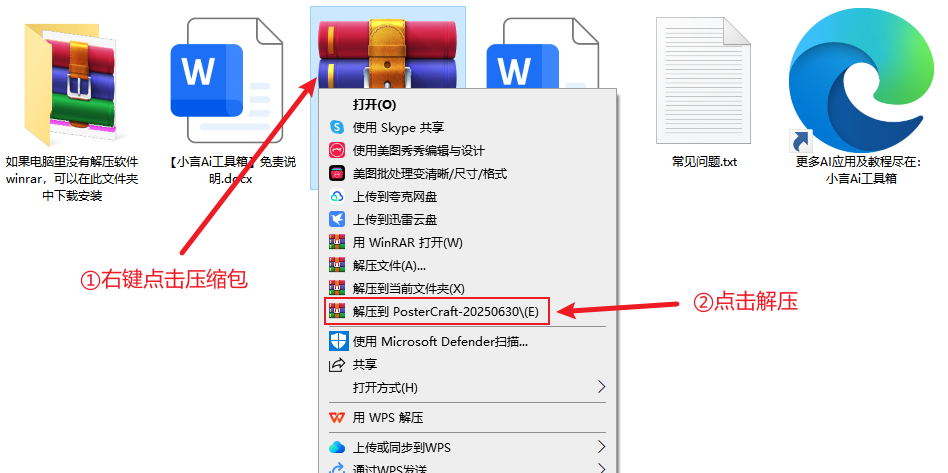
① 打开下载页面(https://www.xyanai.com/2047.html)点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错
![]()
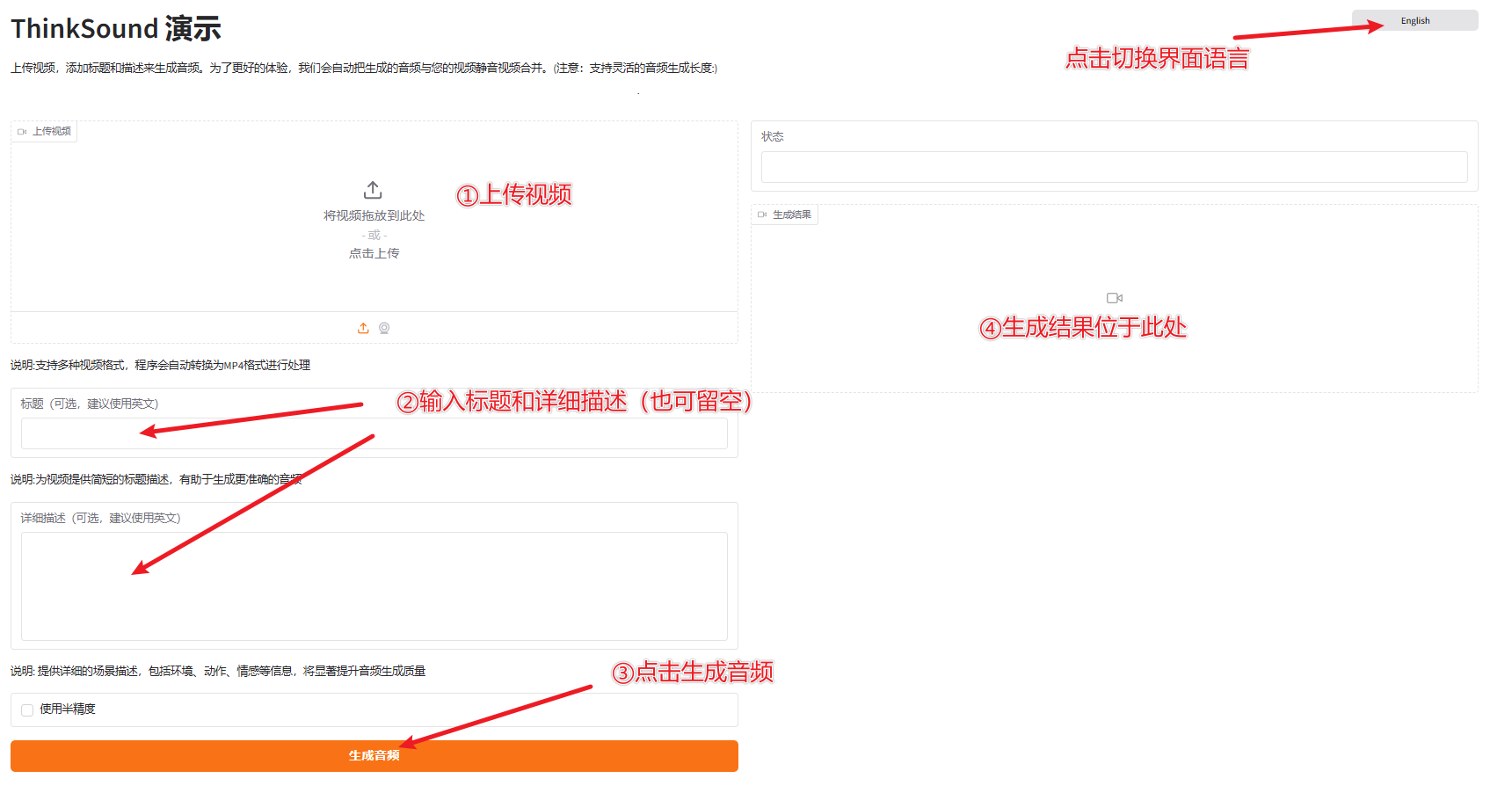
② 双击“启动程序.exe”,稍等片刻会在浏览器中自动打开操作界面

③上传视频,输入标题及详细描述(建议用英文),也可不填,程序会自动识别视频内容并配音,最后点击“生成音频”,生成结果位于右侧
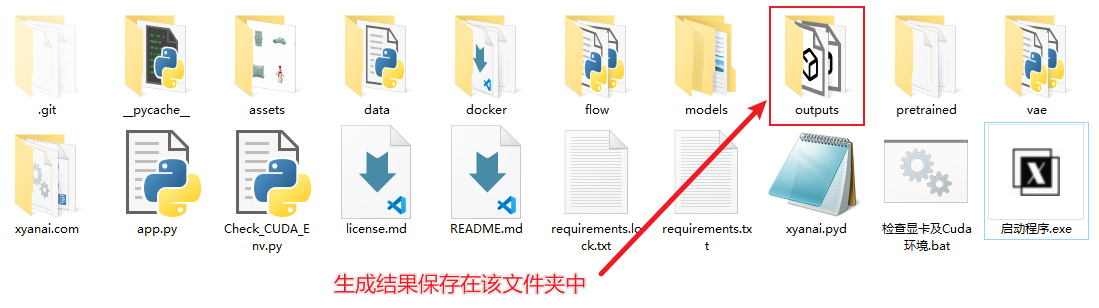
④ 生成结果也会保存在文件包中的“outputs”文件夹中
总结
ThinkSound 是阿里通义语音团队推出的一款智能音频生成模型,专为视频配音打造。它采用链式思考(CoT)推理机制,能像专业音效师一样逐步分析视频内容,生成与画面完美同步的高保真音效。模型融合多模态大语言模型、统一音频生成框架和结构化音频数据集(AudioCoT),具备强大的理解和创作能力,广泛适用于影视、游戏、广告、教育和VR/AR等领域,让AI配音更智能、更精准、更有创意。


